LiteLLM Proxy: cómo montar un gateway de IA para controlar coste, claves y modelos
LiteLLM Proxy no es solo un adaptador para llamar a muchos modelos. Bien usado, es la capa donde un equipo convierte el uso de IA en infraestructura gobernable: claves, presupuesto, rutas, trazas y permisos antes de que cada agente consuma por libre.
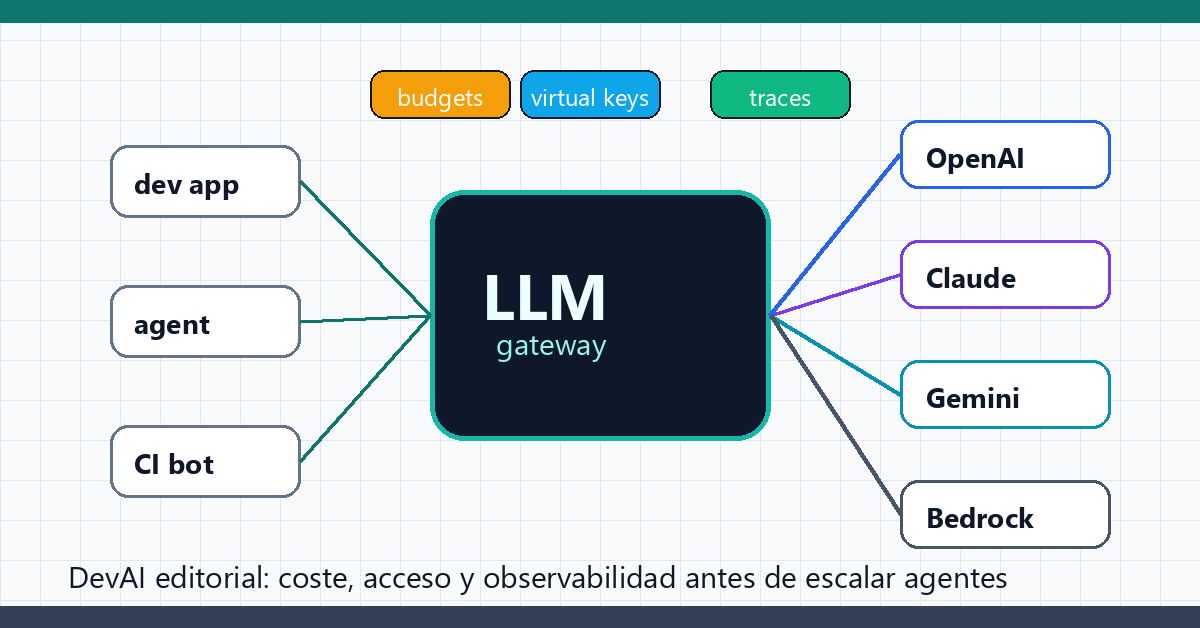
LiteLLM Proxy no es solo un adaptador para llamar a muchos modelos. Bien usado, es la capa donde un equipo convierte el uso de IA en infraestructura gobernable: claves, presupuesto, rutas, trazas y permisos antes de que cada agente consuma por libre.
LiteLLM Proxy es un gateway OpenAI-compatible para poner una capa común delante de OpenAI, Anthropic, Gemini, Bedrock, Azure, modelos locales y otros proveedores. La gracia no es solo cambiar de modelo: es centralizar autenticación, budgets, rate limits, spend tracking, routing, logs y acceso MCP.
Checklist
Qué es LiteLLM Proxy y qué problema resuelve
Una definición citable: LiteLLM Proxy es un gateway self-hosted compatible con clientes OpenAI que enruta peticiones a múltiples proveedores LLM y aplica controles operativos como claves virtuales, presupuestos, límites, trazas, logs y políticas de acceso.
No lo confundas con el SDK Python de LiteLLM. El SDK ayuda a llamar modelos desde una aplicación. El proxy es una pieza de plataforma: una URL común, una capa de autenticación, un plano de control y una base de datos para saber quién gastó qué.
El caso típico aparece cuando un equipo mezcla Copilot, agentes internos, scripts con OpenAI SDK, pruebas con Claude, modelos de Bedrock y prototipos con Gemini. Sin gateway, el coste y los permisos viven dispersos en variables de entorno, tarjetas de crédito y dashboards distintos.
Recibe una lectura semanal de herramientas IA para devs
Si quieres seguir gateways de IA, costes por modelo, agentes, MCP y patrones reales de producción sin leer cada changelog, DevAI Semanal te lo resume cada semana en un email de 5 minutos.
Suscribirme gratis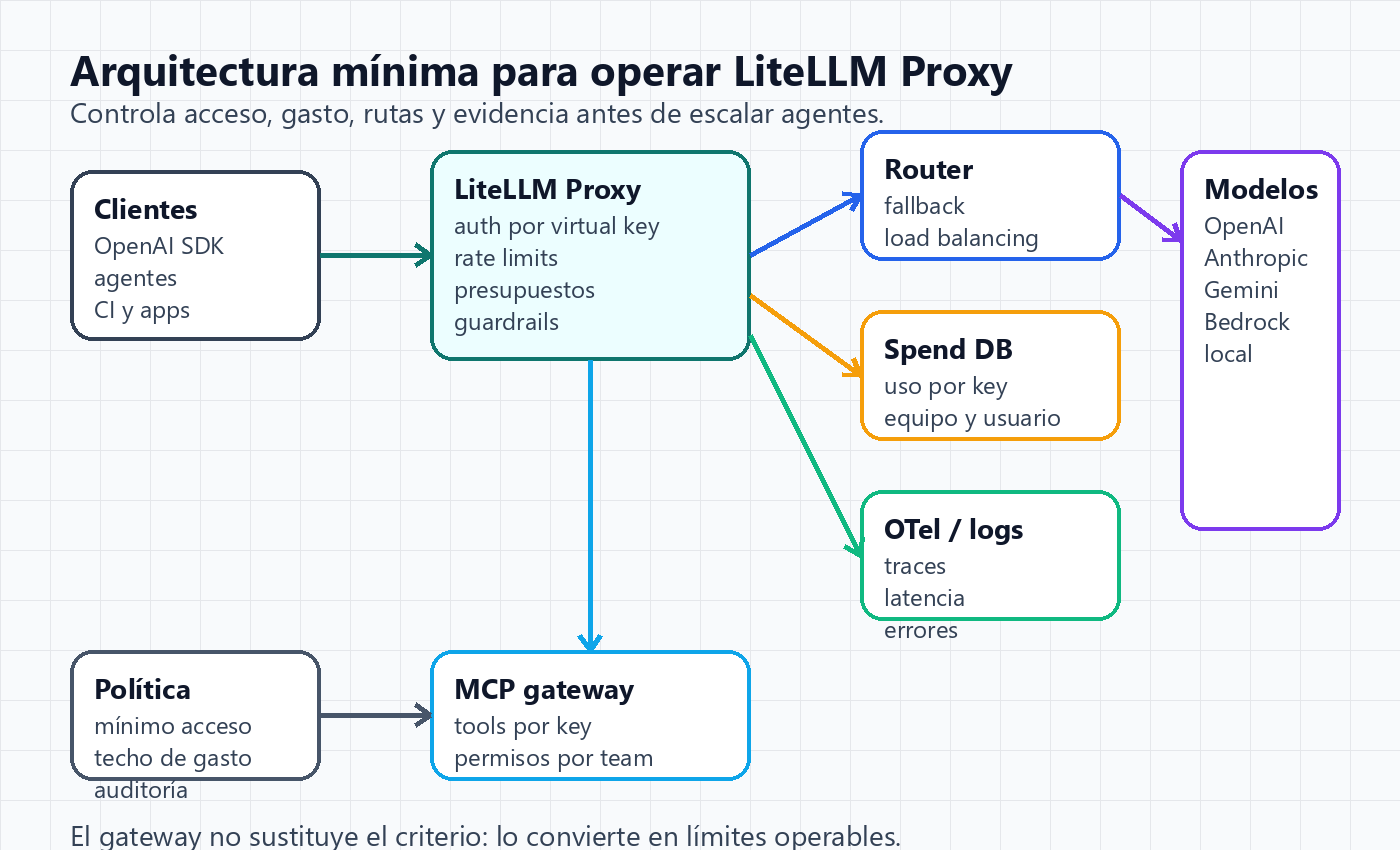
Arquitectura mínima que sí tiene sentido
Empieza con una topología simple: clientes internos apuntan a `base_url=http://tu-proxy:4000`, cada cliente usa una virtual key, el proxy consulta configuración y base de datos, aplica límites, enruta al proveedor y registra gasto y trazas.
Puntos a revisar
Lo que conviene comprobar
La documentación de arquitectura de LiteLLM describe el flujo en piezas claras: validar Bearer token, comprobar budget, aplicar rate limits globales o por key/user/team, pasar por el router, llamar al proveedor y actualizar usage en tareas posteriores.
Esa secuencia importa porque te da puntos de fallo observables. Si una petición no sale, puedes distinguir entre clave inválida, budget agotado, rate limit, proveedor caído, fallback mal configurado o error del cliente.
Checklist
Virtual keys: no repartas claves reales de proveedores
La primera decisión seria es dejar de dar `OPENAI_API_KEY`, `ANTHROPIC_API_KEY` o credenciales de cloud a cada app. LiteLLM permite crear virtual keys para el proxy y controlar acceso a modelos, gasto y metadatos sin exponer la clave real del proveedor.
Para devs locales, usa claves de usuario con presupuesto pequeño. Para producción, usa service accounts o claves de equipo que no dependan de una persona concreta. Para CI, claves separadas por pipeline y entorno.
La documentación de RBAC distingue usuarios internos, equipos, organizaciones y virtual keys asociadas a usuario, team o ambos. Esa distinción no es burocracia: es lo que permite apagar un usuario sin romper producción o atribuir gasto sin compartir una clave global.
Checklist
Budgets y rate limits: pon techo antes del incidente
Un budget no es solo una alerta financiera. Es un freno técnico. LiteLLM puede controlar gasto por key, usuario y equipo, y también budgets por proveedor, modelo o tag según la configuración.
El primer mes no intentaría optimizar al céntimo. Pondría límites conservadores, tags de producto o workflow y un dashboard semanal: coste por equipo, coste por agente, modelos caros, rate limits alcanzados y peticiones rechazadas por budget.
Una política razonable: dev local con techo bajo y reset diario, staging con techo medio, producción con límite mensual y alertas, agentes autónomos con techo por sesión. Si un agente puede iterar, el límite por sesión es tan importante como el límite mensual.
Mi regla: fallback automático para degradación tolerable; aprobación o feature flag para degradación que afecta decisiones de negocio, acciones mutantes, seguridad o generación de código crítico.
OpenTelemetry y logs: sin trazas, solo tienes una factura
LiteLLM tiene integraciones de observabilidad y una ruta OpenTelemetry para enviar trazas a herramientas compatibles. La documentación reciente menciona una integración v2 que produce trazas por request con spans para HTTP, auth, guardrails, llamada LLM y escrituras en base de datos.
Lo mínimo que mediría: modelo solicitado, modelo usado, virtual key, equipo, usuario o tenant anonimizado, latencia, tokens, coste, errores, fallback, rate limit, budget rejection, tool calls MCP y resultado aceptado por humanos cuando exista revisión.
Ojo con logging de prompts y respuestas. Observabilidad no significa guardar secretos. Define redacción, retención y campos prohibidos antes de enviar trazas a un SaaS externo.
Ejemplo de configuración inicial
Para una prueba local, la documentación permite arrancar el proxy con CLI o Docker y llamar al endpoint con cualquier cliente OpenAI-compatible cambiando `base_url`. La parte seria llega cuando añades base de datos y master key para gestionar virtual keys.
Puntos a revisar
Lo que conviene comprobar
Un `config.yaml` mínimo debería declarar modelos con nombres internos estables, variables de entorno para API keys reales, `general_settings.master_key`, conexión a Postgres si quieres key management persistente y límites de budget/rate limit fuera del código de la aplicación.
No nombres tus modelos internos igual que el proveedor si quieres abstracción real. Usa nombres como `coding-fast`, `coding-deep`, `support-cheap` o `extract-structured`. Así puedes cambiar backend sin reeducar cada app.
Plan de despliegue en una semana
- Día 1: inventario de clientes actuales, proveedores, claves y flujos de IA.
- Día 2: proxy local con dos modelos y un cliente OpenAI-compatible apuntando a `base_url` del proxy.
- Día 3: Postgres, master key, virtual keys por entorno y presupuesto bajo de prueba.
- Día 4: tags por producto o workflow, spend tracking y dashboard básico.
- Día 5: rate limits y budgets por usuario, equipo o service account.
- Día 6: routing/fallback solo para flujos no críticos.
- Día 7: OpenTelemetry, alertas, runbook de rotación de claves y política de modelos permitidos.
Checklist
Errores que evitaría
- El primero es convertir el gateway en un proxy transparente que no decide nada. Si todas las claves pueden llamar todos los modelos sin budget ni trazas, solo añadiste latencia.
- El segundo es meter todos los proveedores y modelos desde el día uno. Empieza con dos rutas: una barata/rápida y una cara/profunda. Lo demás llega cuando hay uso real.
- El tercero es usar budgets como sustituto de ownership. Si nadie revisa excepciones, tags, modelos caros y fallos de fallback, el proxy será otro dashboard ignorado.
Checklist de producción
- Define owners del gateway y del gasto de IA.
- Separa claves reales de proveedores y virtual keys del proxy.
- Usa Postgres para key management persistente.
- Crea claves distintas para dev, CI, staging, producción y agentes autónomos.
- Limita modelos por key, equipo o caso de uso.
- Configura budgets y rate limits antes de abrir acceso amplio.
- Registra coste por key, usuario, equipo y workflow.
- Activa trazas y decide qué campos se redactan.
- Documenta fallback y no lo uses para cambiar calidad sin evidencia.
- Para MCP, separa tools de lectura y mutación con permisos distintos.
Preguntas frecuentes
¿Qué es LiteLLM Proxy?
LiteLLM Proxy es un AI gateway self-hosted compatible con clientes OpenAI que centraliza acceso a múltiples proveedores LLM, virtual keys, budgets, rate limits, routing, logs, trazas y control de gasto.
¿LiteLLM Proxy reemplaza al SDK de OpenAI?
No. Muchos clientes OpenAI-compatible pueden seguir usándose cambiando el `base_url` hacia el proxy. El proxy se coloca entre tu aplicación y los proveedores.
¿Necesito Postgres para usar LiteLLM Proxy?
Para una prueba simple no siempre, pero para key management, virtual keys persistentes y spend tracking serio conviene desplegarlo con base de datos.
¿LiteLLM Proxy sirve para controlar costes de agentes?
Sí, especialmente si cada agente usa una virtual key propia, budgets por sesión o equipo, tags de workflow y trazas que permitan atribuir consumo.
¿LiteLLM Proxy funciona con MCP?
LiteLLM incluye MCP Gateway para listar y llamar tools, prompts y recursos con control de acceso por key, team u organización.
¿Cuál es el riesgo principal?
Creer que un gateway sustituye política. Si no defines modelos permitidos, budgets, retención de logs, permisos MCP y ownership, solo centralizas el caos.
Fuentes y referencias
También te puede interesar
Métricas para agentes de códigoOpenAI Agents SDK: MCP, guardrails y tracingClaude Agent SDK en Python y TypeScriptMCP en producción: seguridad y permisosRTK: reducir tokens en agentes de IARecibe una lectura semanal de herramientas IA para devs
Cada semana te resumo herramientas de IA para devs, agentes, MCP, seguridad y workflows en un email de 5 minutos. En español y sin ruido.
Suscribirme gratis

