Pydantic AI: cómo crear agentes Python tipados sin perder control en producción
Pydantic AI no es otro wrapper bonito para prompts. Su valor está en obligarte a tratar un agente como software: contratos de salida, dependencias explícitas, herramientas validadas, límites de uso, trazas y evals.

Pydantic AI no es otro wrapper bonito para prompts. Su valor está en obligarte a tratar un agente como software: contratos de salida, dependencias explícitas, herramientas validadas, límites de uso, trazas y evals.
Pydantic AI es un framework Python para construir aplicaciones y agentes de IA con el estilo mental de FastAPI: tipos, validación, inyección de dependencias, herramientas declarativas, salida estructurada, observabilidad y evals.
Checklist
Por qué Pydantic AI importa para devs Python
Una definición citable: Pydantic AI es un framework de agentes para Python que convierte prompts, herramientas, dependencias y resultados de modelos en contratos tipados que puedes validar, probar y observar como parte de una aplicación normal.
La mayoría de demos de agentes fallan por el mismo motivo: tratan el LLM como una caja mágica que devuelve texto. En producción eso no basta. Necesitas saber qué forma debe tener la respuesta, qué herramientas puede llamar, cuántas veces, con qué datos y bajo qué límites.
Pydantic AI ataca ese problema desde una idea muy pragmática: si ya usas Pydantic para validar entradas y salidas en APIs, usa el mismo músculo para validar decisiones generadas por modelos.
Recibe una lectura semanal de herramientas IA para devs
Si quieres seguir frameworks de agentes como Pydantic AI, OpenAI Agents SDK, Claude Agent SDK, MCP y evals sin leer veinte changelogs a la semana, DevAI Semanal te lo resume en un email de 5 minutos.
Suscribirme gratis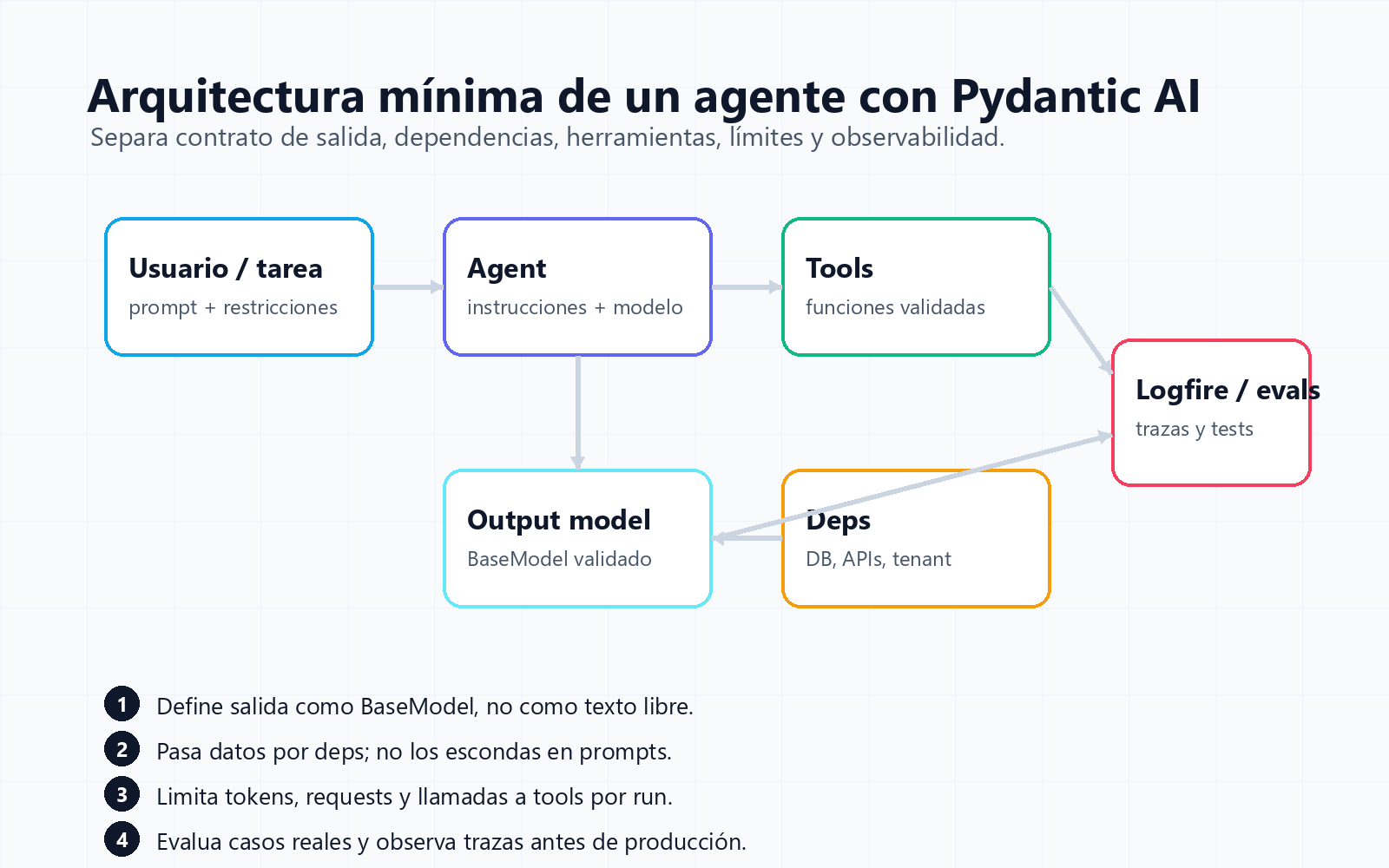
Primer ejemplo ejecutable: salida tipada
Este ejemplo no intenta ser sofisticado. La idea es mostrar el patrón: un `BaseModel` define la salida, el agente la valida y tu código consume `result.output` como objeto Python, no como JSON pegado con cinta.
from pydantic import BaseModel, Field
from pydantic_ai import Agent
class ReviewDecision(BaseModel):
verdict: str = Field(description="approve, request_changes or needs_human")
risk: int = Field(ge=0, le=10)
reasons: list[str]
agent = Agent(
"openai:gpt-5.2",
output_type=ReviewDecision,
instructions=(
"Eres un revisor senior. Devuelve una decision breve, "
"un riesgo de 0 a 10 y razones accionables."
),
)
result = agent.run_sync(
"El PR cambia autenticacion, no trae tests y toca sesiones."
)
decision = result.output
print(decision.verdict, decision.risk, decision.reasons)Checklist
Qué gana el output tipado
Ganas una frontera concreta entre IA y producto. Si el modelo responde con una forma inválida, no lo conviertes silenciosamente en estado de negocio. Lo validas, reintentas dentro del presupuesto o fallas de forma explícita.
Esto es especialmente importante en agentes que clasifican tickets, generan acciones, evalúan riesgos, enrutan incidencias, preparan PRs o deciden si una tarea necesita humano. En esos casos, texto bonito no es un contrato.
La documentación de Pydantic AI también remarca que el resultado conserva tipos genéricos, historial y uso de la ejecución. Esa metadata importa cuando quieres depurar por qué una decisión salió cara o mala.
from dataclasses import dataclass
from pydantic import BaseModel
from pydantic_ai import Agent, RunContext, UsageLimits
class Finding(BaseModel):
file: str
problem: str
next_step: str
@dataclass
class RepoDeps:
repo_name: str
index: object
agent = Agent(
"anthropic:claude-sonnet-4-6",
deps_type=RepoDeps,
output_type=list[Finding],
instructions="Encuentra problemas concretos y devuelve acciones pequenas.",
)
@agent.tool
async def search_code(ctx: RunContext[RepoDeps], query: str) -> list[str]:
"""Busca fragmentos relevantes en el indice del repositorio."""
return await ctx.deps.index.search(ctx.deps.repo_name, query, limit=5)
async def review(repo_index):
deps = RepoDeps(repo_name="billing-api", index=repo_index)
return await agent.run(
"Busca riesgos en el modulo de invoices.",
deps=deps,
usage_limits=UsageLimits(request_limit=4, tool_calls_limit=3),
)Tools: la docstring también es interfaz
En Pydantic AI, las funciones registradas como tools exponen argumentos al modelo. Eso significa que nombres, tipos y docstrings son parte de la interfaz. Una tool vaga produce llamadas vagas.
Puntos a revisar
Lo que conviene comprobar
Regla práctica: una tool debe hacer una cosa, aceptar pocos parámetros y devolver datos que no obliguen al modelo a inferir demasiado. Si devuelves una lista gigante de strings, has trasladado el problema al prompt. Si devuelves objetos pequeños y consistentes, reduces alucinaciones operativas.
También conviene separar tools de lectura y tools mutantes. Las primeras pueden tener permisos amplios dentro de un entorno controlado; las segundas necesitan scopes mínimos, logging y aprobación humana cuando tocan repos, tickets, cloud o datos de clientes.
Checklist
MCP: úsalo para capacidades externas, no para saltarte diseño
Pydantic AI puede actuar como cliente MCP y conectar tools locales o remotas mediante `MCPToolset` o la capacidad `MCP`. Eso encaja muy bien con el ecosistema actual: servidores MCP para documentación, repos, observabilidad, datos internos o automatización.
Pero MCP no arregla una arquitectura mala. Si conectas diez servidores sin política, solo has dado más botones al modelo. La pregunta correcta es: qué tool necesita esta tarea, con qué transporte, con qué lifecycle, con qué credenciales y qué salida espero validar después.
Para equipos que ya usan MCP en Copilot, Claude Code o Cursor, Pydantic AI puede ser la capa Python donde conviertes esas capacidades en producto: controlas el cliente, los tipos, el flujo de ejecución y las pruebas.
Checklist
Modelos y proveedores: no cases tu dominio con una API
Pydantic AI abstrae modelos y proveedores: puedes instanciar agentes con nombres tipo `openai:gpt-5.2` o usar clases de modelo/proveedor más explícitas cuando necesitas Azure, OpenAI-compatible providers, LiteLLM, Ollama, GitHub Models u otro gateway.
Esto no significa que cambiar de modelo sea gratis. Cada proveedor tiene límites, perfiles, capacidades de herramientas y detalles de JSON schema. Pero sí te permite aislar el dominio de la aplicación del SDK de un proveedor concreto.
Mi recomendación: empieza con un proveedor explícito en configuración, registra métricas por modelo y guarda casos de evaluación. Cambiar de modelo sin evals es fe, no ingeniería.
Una batería mínima debería incluir: casos felices, inputs ambiguos, intentos de prompt injection, datos incompletos, límite de tools, errores de proveedor, salida inválida y ejemplos donde el agente debe decir `necesita humano`.
Checklist de producción
- Define `output_type` para cualquier decisión que consuma tu aplicación.
- Pasa datos vivos por `deps`, no por prompts enormes.
- Separa tools de lectura y tools mutantes.
- Pon `UsageLimits` en runs que puedan llamar tools.
- Registra modelo, tokens, tool calls, latencia, reintentos y coste.
- Crea evals antes de cambiar de modelo o prompt principal.
- Conecta MCP solo para capacidades concretas y auditables.
- Haz que el agente pueda decir `no sé` o `necesita humano`.
- Versiona prompts, schemas y datasets de evaluación junto al código.
Errores que evitaría
El primero es vender Pydantic AI como garantía de verdad. Validar estructura no valida factualidad. Un `BaseModel` puede contener basura perfectamente tipada si no hay tools, fuentes o evaluadores.
Puntos a revisar
Lo que conviene comprobar
El segundo es meter todos los datos en instrucciones. Si el prompt contiene secretos, datos de cliente o reglas efímeras, cada run se vuelve más caro, menos auditable y más difícil de limpiar.
El tercero es conectar MCP como catálogo infinito. Un agente con demasiadas tools se parece a un junior con permisos de producción y una wiki enorme: quizá acierte, pero no es un control.
El cuarto es no medir reintentos de validación. Si tu schema es demasiado estricto o ambiguo, el agente puede gastar tokens intentando satisfacer una forma que el prompt no explica bien.
Checklist
Cuándo elegir Pydantic AI frente a OpenAI o Claude SDK
Elige Pydantic AI si tu equipo trabaja en Python, ya usa Pydantic/FastAPI, necesita salida tipada, quiere cambiar de proveedor con menos fricción y va a tratar agentes como componentes de backend.
Elige el SDK nativo de OpenAI o Anthropic si necesitas exprimir una capacidad específica del proveedor, si tu app depende de una superficie muy concreta o si prefieres controlar directamente cada request.
La decisión práctica no es framework contra framework. Es capa de dominio contra API de proveedor. Pydantic AI brilla cuando quieres una capa de dominio estable por encima de modelos que van a cambiar.
Checklist
Plan de adopción de una semana
- Día 1: elige un caso acotado donde la salida pueda representarse como `BaseModel`: clasificación de tickets, revisión de riesgo, resumen técnico o extracción estructurada.
- Día 2: escribe el agente con una sola tool de lectura y `UsageLimits` bajos. No conectes todavía acciones mutantes.
- Día 3: añade diez casos de evaluación: cinco normales, tres ambiguos y dos hostiles.
- Día 4: instrumenta trazas y registra uso por ejecución. Mira reintentos, tool calls y latencia antes de optimizar prompts.
- Día 5: prueba un segundo modelo o gateway y compara evals. Si no puedes comparar, todavía no estás listo para producción.
Preguntas frecuentes
¿Qué es Pydantic AI?
Pydantic AI es un framework Python para construir aplicaciones y agentes de IA con contratos tipados, herramientas validadas, dependencias explícitas, observabilidad y evals.
¿Pydantic AI reemplaza a OpenAI Agents SDK o Claude Agent SDK?
No necesariamente. Puede usarse como capa Python de dominio cuando quieres tipos, validación y portabilidad; los SDK nativos siguen siendo útiles para capacidades específicas del proveedor.
¿Pydantic AI soporta MCP?
Sí. Pydantic AI puede actuar como cliente MCP y conectar servidores locales o remotos para usar sus tools dentro de ejecuciones de agente.
¿La salida tipada evita alucinaciones?
No. Evita que la forma sea inválida, pero no garantiza que el contenido sea verdadero. Para factualidad necesitas fuentes, tools, validadores y evals.
¿Cuándo merece la pena usar Pydantic Evals?
Cuando vas a cambiar prompts, modelos, tools o workflows y necesitas comparar comportamiento con casos representativos, no solo confiar en una demo.
¿Pydantic AI sirve para producción?
Sí, si lo usas con límites de uso, observabilidad, evals, control de tools y revisión humana en acciones de riesgo. Sin eso, sigue siendo una demo con buen tipado.
Fuentes y referencias
También te puede interesar
OpenAI Agents SDK: MCP, guardrails y tracingClaude Agent SDK en Python y TypeScriptLiteLLM Proxy: gateway IA, costes y modelosMCP outputSchema y structuredContentMétricas para agentes de códigoRecibe una lectura semanal de herramientas IA para devs
Cada semana te resumo herramientas de IA para devs, agentes, MCP, seguridad y workflows en un email de 5 minutos. En español y sin ruido.
Suscribirme gratis