Cloudflare Agents SDK: cómo crear agentes con estado en Durable Objects
Cloudflare Agents SDK no es otro wrapper de prompts. Es un runtime TypeScript para agentes persistentes: cada instancia vive en un Durable Object con SQL, estado sincronizado, WebSockets, tareas programadas y herramientas MCP.
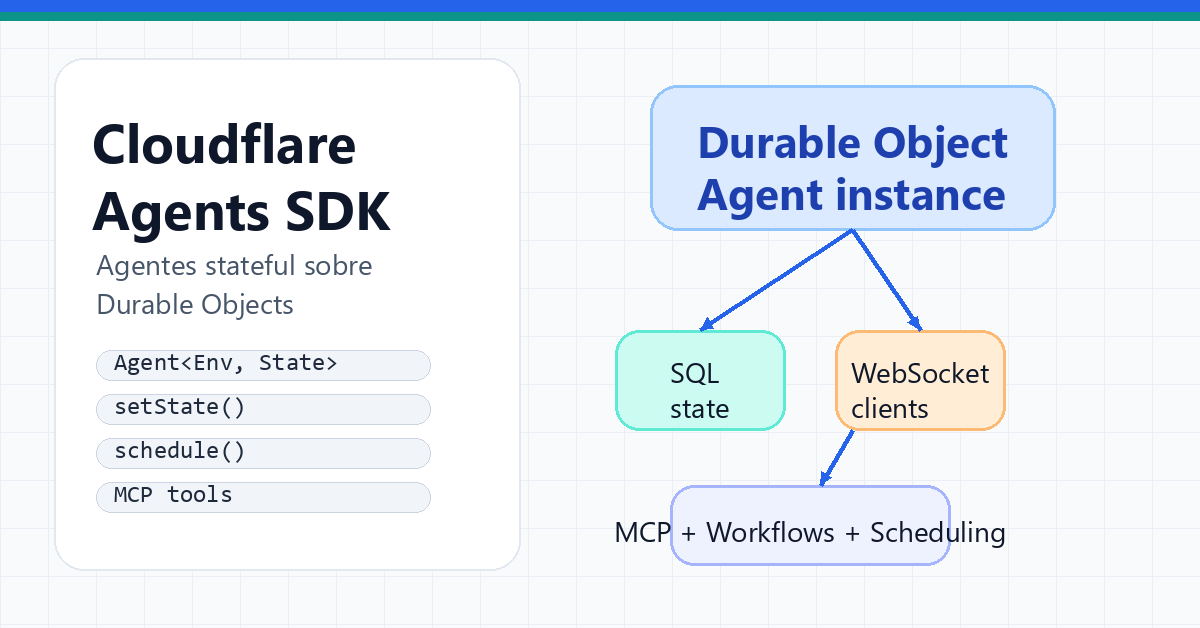
Cloudflare Agents SDK no es otro wrapper de prompts. Es un runtime TypeScript para agentes persistentes: cada instancia vive en un Durable Object con SQL, estado sincronizado, WebSockets, tareas programadas y herramientas MCP.
Cloudflare Agents SDK es un runtime TypeScript para crear agentes de IA persistentes sobre Cloudflare Workers y Durable Objects. La diferencia importante frente a un endpoint serverless normal es que cada agente tiene identidad duradera, SQL local, estado sincronizado, conexiones WebSocket, tareas programadas y una ruta natural hacia MCP, Workflows y herramientas del ecosistema Cloudflare.
Checklist
Qué es Cloudflare Agents SDK y qué no es
Una definición citable: Cloudflare Agents SDK es una capa de runtime para agentes stateful donde una clase `Agent` encapsula estado, conexiones, métodos invocables, llamadas a modelos, herramientas, errores y tareas programadas, ejecutándose sobre Durable Objects.
No es un modelo, no es un prompt mágico y no reemplaza la disciplina de producto. El SDK te da primitivas para que un agente recuerde, despierte, reciba eventos, coordine trabajo y hable con clientes en tiempo real. La calidad sigue dependiendo de tus tools, permisos, evals, límites y diseño del workflow.
La lectura práctica es esta: Cloudflare intenta convertir el problema de `dónde vive mi agente` en infraestructura gestionada. En lugar de reconstruir sesión, memoria, WebSocket, cola y cron en piezas separadas, puedes colgarlo de una instancia direccionable por nombre.
La pregunta buena no es `¿puedo hacer un chatbot?`. La pregunta buena es: ¿qué entidad del producto necesita recordar, recibir eventos, ejecutar tareas y mantener conexiones? Esa entidad debería mapearse a una instancia de agente.
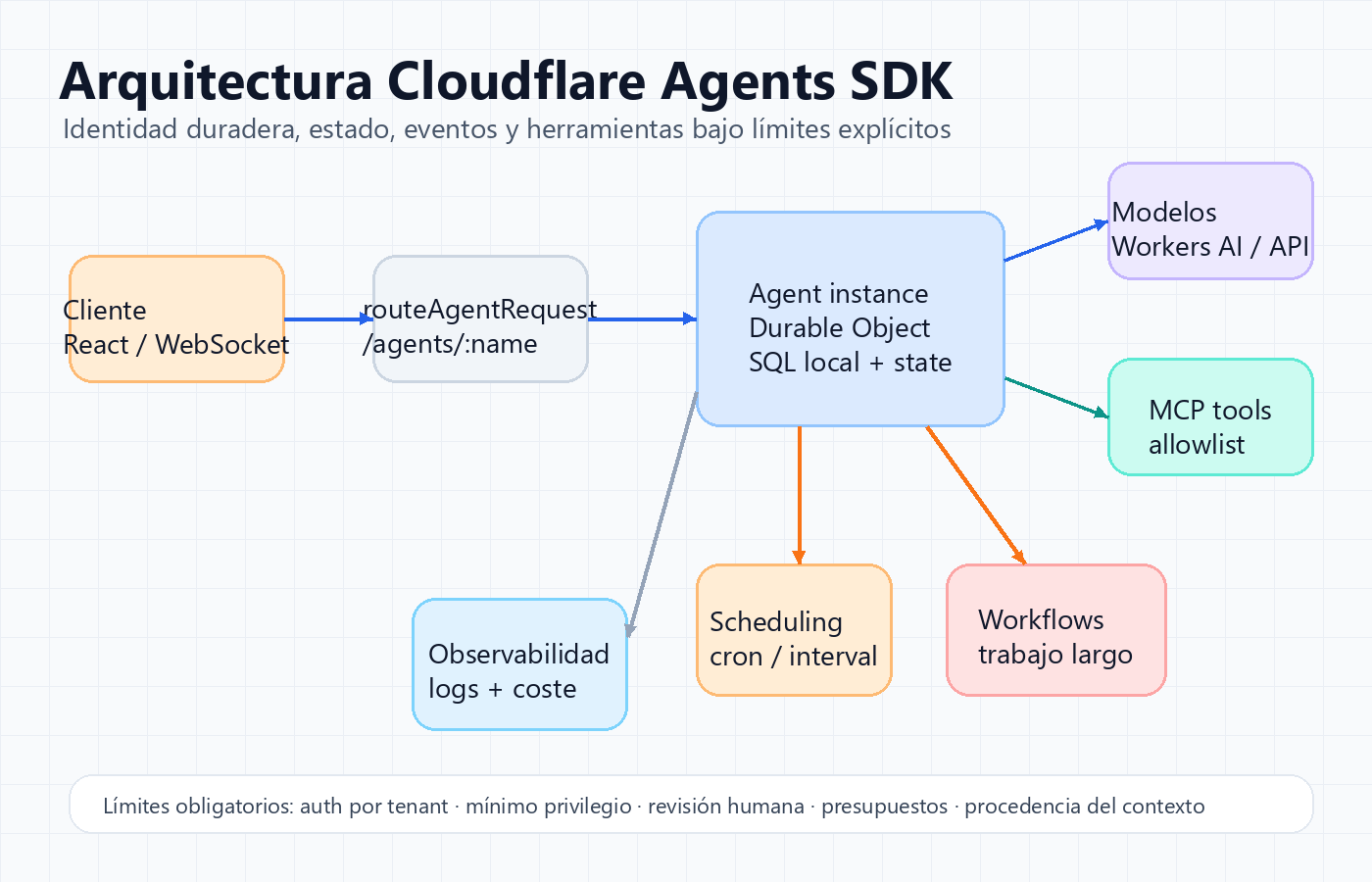
Arquitectura mínima que sí desplegaría
La versión mínima seria tiene seis piezas. Primero, una clase `Agent<Env, State>` con un estado pequeño y serializable. Segundo, `routeAgentRequest` para enrutar peticiones a instancias por nombre. Tercero, una política explícita de nombres: usuario, equipo, sala, ticket o repositorio. Cuarto, SQL local solo para datos que pertenecen a esa instancia. Quinto, WebSockets o SSE solo cuando el usuario necesita ver progreso. Sexto, observabilidad y límites antes de tools mutantes.
No empezaría conectando Browser, MCP, pagos, email y Workflows el día uno. Empezaría con una tarea de lectura, una tool controlada y un estado mínimo. Cuando eso sea observable, añadiría scheduling. Cuando scheduling no baste para trabajo largo con reintentos, movería esa parte a Workflows.
La arquitectura debe dejar claro qué vive en el agente y qué vive fuera. Preferencias, progreso y memoria local encajan en el agente. Datos de negocio compartidos, billing, permisos corporativos y auditoría de largo plazo suelen pertenecer a sistemas externos que el agente consulta con credenciales limitadas.
Código mínimo: estado, routing y RPC
<pre><code class="language-ts">import { Agent, callable, routeAgentRequest } from "agents"; type State = { lastTask: string | null; completed: number; }; export class RepoAgent extends Agent<Env, State> { initialState: State = { lastTask: null, completed: 0 }; @callable() async summarizeRepo(task: string) { this.setState({ ...this.state, lastTask: task }); // Aqui llamarias a un modelo y a tools de lectura con permisos limitados. const summary = `Resumen pendiente para: ${task}`; this.setState({ ...this.state, completed: this.state.completed + 1 }); return { summary, completed: this.state.completed }; } } export default { async fetch(request: Request, env: Env) { return (await routeAgentRequest(request, env)) ?? new Response("Not found", { status: 404 }); }, } satisfies ExportedHandler<Env>;</code></pre>
¿Te está sirviendo? Hay una dosis cada semana
Te resumo herramientas de IA para devs, agentes, MCP, seguridad y workflows en un email de 5 minutos. En español y sin ruido.
Suscribirme gratisPuntos a revisar
Lo que conviene comprobar
El detalle que importa no es la sintaxis del contador. Es el contrato: estado pequeño, método invocable, actualización explícita y routing que devuelve siempre la misma instancia cuando el nombre coincide. Eso hace posible reanudar trabajo sin inventarte otro session store.
Checklist
Configurar Durable Objects sin olvidar migraciones
Agents SDK depende de Durable Objects. En `wrangler.jsonc`, cada clase de agente necesita binding y migración SQLite. Si cambias el nombre de la clase o creas otro tipo de agente, trátalo como cambio de infraestructura, no como refactor inocente.
<pre><code class="language-jsonc">{ "durable_objects": { "bindings": [ { "name": "RepoAgent", "class_name": "RepoAgent" } ] }, "migrations": [ { "tag": "v1", "new_sqlite_classes": ["RepoAgent"] } ] }</code></pre>
Mi regla: versiona la configuración junto al agente y revisa migraciones en PR. Un agente con memoria persistente no se comporta como una función desechable; si rompes identidad o esquema, rompes continuidad para usuarios reales.
Checklist
Estado: cuándo usar `setState` y cuándo usar SQL
Usa `setState` para el estado pequeño que el cliente necesita ver sincronizado: fase actual, progreso, última acción, preferencias simples o bandera de aprobación. Es persistente, se guarda en SQLite y se sincroniza en tiempo real con clientes conectados.
Usa `this.sql` para historial, filas consultables, eventos, resultados intermedios o datos que no quieres enviar enteros a cada cliente. La tentación de meter todo en `state` es fuerte porque funciona rápido; también es la forma más fácil de crear payloads enormes y acoplar UI con almacenamiento interno.
Estado de agente no es memoria infinita para el LLM. Si usas estado como contexto del modelo, resume y selecciona. Poner transcripciones completas en cada turno dispara coste, latencia y riesgo de prompt injection acumulada.
No usaría scheduling para procesos de horas con reintentos complejos y compensaciones. Ahí entran Workflows. Scheduling es ideal para recordatorios, polling prudente, reintentos simples, digest diarios y mantenimiento de una instancia concreta.
MCP: conectar herramientas sin abrir toda la cuenta
Cloudflare Agents puede consumir MCP y también servir herramientas mediante MCP. Eso encaja muy bien con agentes internos: el agente mantiene sesión y permisos locales, mientras MCP expone capacidades concretas a modelos o clientes compatibles.
Pero MCP no es una licencia para conectar toda tu infraestructura. Usa OAuth o credenciales por ámbito, separa lectura de escritura, registra tool calls y limita qué servidores puede usar cada tipo de agente. Si el agente opera sobre Cloudflare, GitHub o sistemas internos, el blast radius lo define tu política de tools, no el SDK.
Para DevAI, la pauta sería: MCP para capacidades bien acotadas, output estructurado para resultados auditables y revisión humana para acciones irreversibles. Sin esas tres cosas, solo has creado una consola de administración con lenguaje natural.
WebSockets y cliente React: progreso sin polling torpe
El cliente puede conectarse al agente con `useAgent` o `useAgentChat`. Eso permite leer estado sincronizado, invocar métodos y mostrar progreso sin montar un gateway WebSocket separado. Para UIs de chat, `AIChatAgent` y `useAgentChat` añaden persistencia de mensajes y recuperación de streams.
Puntos a revisar
Lo que conviene comprobar
No pondría todo el producto dentro del hook. La UI debe tratar el agente como runtime de interacción, no como base de datos global. El patrón limpio es: estado visible en el agente, datos de negocio en APIs normales, y eventos largos como progreso o milestones.
Si el usuario cierra la pestaña o se cae la conexión, la promesa del runtime es que pueda volver a la misma instancia. Diseña la UI para esa realidad: muestra última fase, último error, siguiente acción disponible y si hay aprobación humana pendiente.
Checklist
Seguridad y permisos: el agente no es el perímetro
Cloudflare te da identidad duradera del agente, pero eso no equivale a autorización de negocio. Comprueba usuario, tenant y permisos en cada acción sensible. El nombre de instancia ayuda a enrutar; no debería ser el único control de acceso.
Separa secrets por entorno, scope y tool. Un agente de soporte no necesita credenciales de despliegue. Un agente de repositorio no necesita escribir en billing. Un agente que genera resúmenes no necesita ejecutar acciones mutantes. Lo aburrido sigue siendo lo correcto: mínimo privilegio, allowlists, logs y revisión humana.
También vigilaría prompt injection persistente. Un agente que recuerda instrucciones, páginas visitadas o resultados de tools puede acumular datos hostiles. Resume, etiqueta procedencia y evita que contenido recuperado se convierta en instrucciones del sistema.
Checklist
Observabilidad y coste
Mide por instancia y por tipo de trabajo: turnos, tools, modelo, tokens, duración, reintentos, errores, tareas programadas y workflows iniciados. Si usas AI Gateway, aprovecha caching, rate limits, fallback y logs para ver consumo real en vez de adivinarlo por factura.
La métrica que más me interesa no es `mensajes respondidos`. Es `decisiones útiles completadas sin intervención peligrosa`. Un agente que contesta mucho pero dispara workflows innecesarios, llama tools caras o requiere revisión manual constante no está ahorrando tiempo.
Para producción pondría presupuestos por agente, por usuario y por acción. Cuando un agente cruza umbral, debe degradar: modelo más barato, menos contexto, cola asíncrona o pedir aprobación. Sin degradación, el primer incidente será coste o permisos.
La comparación honesta: Cloudflare no gana por tener el mejor loop de razonamiento. Gana cuando quieres dejar de fabricar infraestructura alrededor del loop. Si tu equipo ya tiene backend robusto, colas, WebSockets y cron bien resueltos, el valor incremental baja.
Plan de adopción en cinco días
- Día 1: elige una entidad clara, por ejemplo `repo-agent/<owner>/<repo>` o `support-agent/<ticket-id>`, y crea un agente sin tools mutantes.
- Día 2: añade estado mínimo, SQL para eventos y una UI que muestre fase, último error y progreso.
- Día 3: conecta un modelo y una sola tool de lectura. Mide tokens, latencia y errores por instancia.
- Día 4: añade scheduling para una tarea real, como digest diario, revisión de cola o reintento con backoff.
- Día 5: decide si necesitas MCP, Workflows o ambos. Si no puedes explicar permisos y recuperación, no añadas más herramientas todavía.
Conclusión
Cloudflare Agents SDK es interesante porque ataca una parte poco glamourosa de los agentes: dónde viven, cómo recuerdan, cómo se reconectan, cómo despiertan y cómo ejecutan trabajo duradero. Eso no convierte cualquier chatbot en producto, pero sí reduce mucha infraestructura accidental.
Puntos a revisar
Lo que conviene comprobar
Mi recomendación es usarlo cuando el agente tenga vida propia: sesiones, estado, eventos, scheduling, progreso y tools. Si solo necesitas transformar un input en JSON, no lo compliques. Pero si estás construyendo un agente que acompaña a un usuario o equipo durante horas o días, Durable Objects como runtime empiezan a tener mucho sentido.
Preguntas frecuentes
¿Qué es Cloudflare Agents SDK?
Cloudflare Agents SDK es un SDK TypeScript para crear agentes de IA persistentes sobre Workers y Durable Objects, con estado, SQL local, WebSockets, scheduling, Workflows y soporte MCP.
¿Cloudflare Agents SDK requiere Durable Objects?
Sí. El modelo de identidad, estado persistente, SQL y conexiones del agente se apoya en Durable Objects y sus bindings de configuración.
¿Puedo usar OpenAI o Anthropic con Cloudflare Agents SDK?
Sí. El runtime puede usar Workers AI o proveedores externos como OpenAI, Anthropic y Gemini; la elección del modelo no es lo mismo que la elección del runtime.
¿Cuándo usar scheduling y cuándo Workflows?
Usa scheduling para tareas simples en una instancia: retrasos, cron, intervalos y reintentos ligeros. Usa Workflows para procesos largos, multi-paso, con reintentos y garantías más fuertes.
¿Cloudflare Agents SDK reemplaza a MCP?
No. MCP es una interfaz de herramientas y contexto. Agents SDK puede consumir o servir MCP, pero sigues necesitando permisos, allowlists y observabilidad.
¿Es mejor que LangGraph o Google ADK?
No universalmente. Cloudflare Agents SDK destaca como runtime stateful para productos web; LangGraph destaca en grafos de ejecución; Google ADK encaja en el ecosistema Google; OpenAI Agents SDK encaja en orquestación OpenAI.
Cómo llevar un agente Cloudflare Agents SDK a producción
- Elegir la entidad de instancia. Decide si cada agente representa un usuario, equipo, sala, ticket, repositorio o proceso programado.
- Crear la clase Agent. Define `Agent<Env, State>` con estado pequeño, métodos invocables y una política clara de nombres.
- Configurar Durable Objects. Añade bindings y migraciones SQLite en `wrangler.jsonc` y revísalos como infraestructura.
- Separar estado y datos. Usa `setState` para estado visible y SQL o APIs externas para historial y datos compartidos.
- Añadir tools con permisos mínimos. Empieza por lectura, registra llamadas y exige aprobación humana para acciones irreversibles.
- Programar trabajo duradero. Usa `schedule` para tareas simples y Workflows para procesos largos con reintentos y recuperación.
- Verificar recuperación. Prueba reconexión WebSocket, hibernación, despliegue, errores de modelo y reanudación antes de exponerlo a usuarios.
Fuentes y referencias
También te puede interesar
OpenAI Agents SDK: MCP, guardrails y tracingMCP en producción: seguridad y permisosMCP outputSchema y structuredContentLiteLLM Proxy: gateway IA, costes y modelosLangGraph: agentes Python con estadoRecibe una lectura semanal de herramientas IA para devs
Cada semana te resumo herramientas de IA para devs, agentes, MCP, seguridad y workflows en un email de 5 minutos. En español y sin ruido.
Suscribirme gratis